
In this age of large astronomical surveys, one major scientific bottleneck is the analysis of enormous data sets. Traditionally, this task requires human input — but could computers eventually take over? A pair of scientists explore this question by testing whether computers can classify galaxies as well as humans.

Examples of disagreement: galaxies that Galaxy-Zoo humans classified as spirals with >95% agreement, but the computer algorithm classified as ellipticals with >70% certainty. Most are cases where the computer got it wrong — but not all of them. [Adapted from Kuminski et al. 2016]
Limits of Citizen Science
Galaxy Zoo is an internet-based citizen science project that uses non-astronomer volunteers to classify galaxy images. This is an innovative way to provide more manpower, but it’s still only practical for limited catalog sizes. How do we handle the data from upcoming surveys like the Large Synoptic Survey Telescope (LSST), which will produce billions of galaxy images when it comes online?
In a recent study by Evan Kuminski and Lior Shamir, two computer scientists at Lawrence Technological University in Michigan, a machine learning algorithm known as Wndchrm was used to classify a dataset of Sloan Digital Sky Survey (SDSS) galaxies into ellipticals and spirals. The authors’ goal is to determine whether their algorithm can classify galaxies as accurately as the human volunteers for Galaxy Zoo.
Automatic Classification
After training their classifier on a small set of spiral and elliptical galaxies, Kuminski and Shamir set it loose on a catalog of ~3 million SDSS galaxies. The classifier first computes a set of 2,885 numerical descriptors (like textures, edges, and shapes) for each galaxy image, and then uses these descriptors to categorize the galaxy as spiral or elliptical.
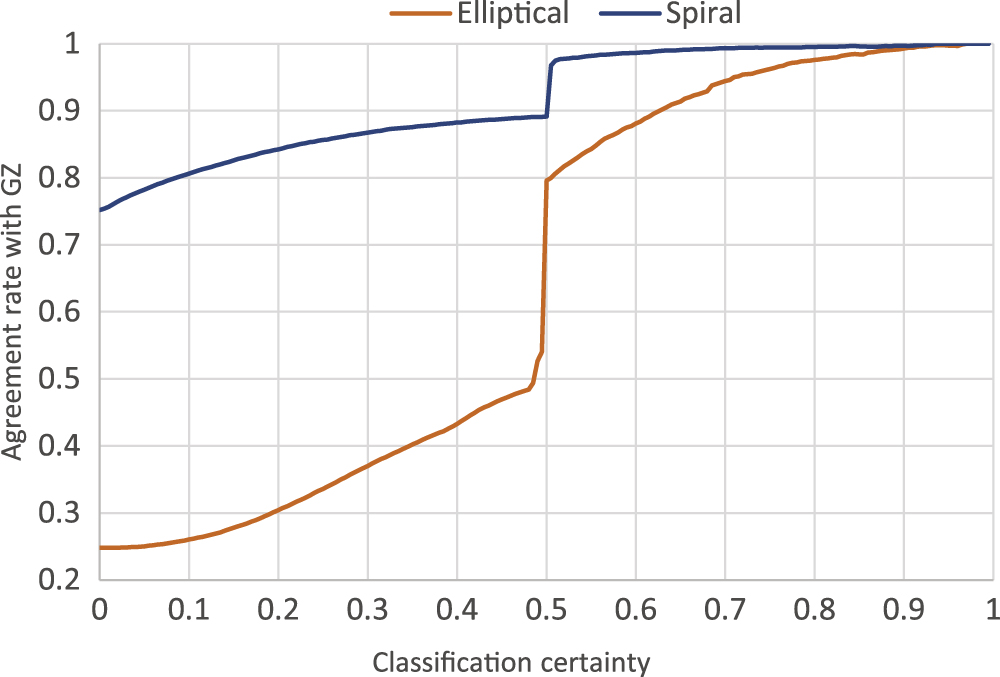
Rate of agreement of the computer classification with human classification (for the Galaxy Zoo “superclean” subset) for different ranges of computed classification certainties. For certainties above 54% for spirals and 80% for ellipticals, the agreement is over 98%. [Kuminski et al. 2016]
Comparing the Outcome
To evaluate the accuracy of the algorithm’s findings, the authors examined SDSS galaxies that had also been classified by Galaxy Zoo. In particular, they used a 45,000-galaxy subset that consists only of “superclean” Galaxy Zoo galaxies — meaning the human volunteers who categorized them were in agreement at a level of 95% or higher.
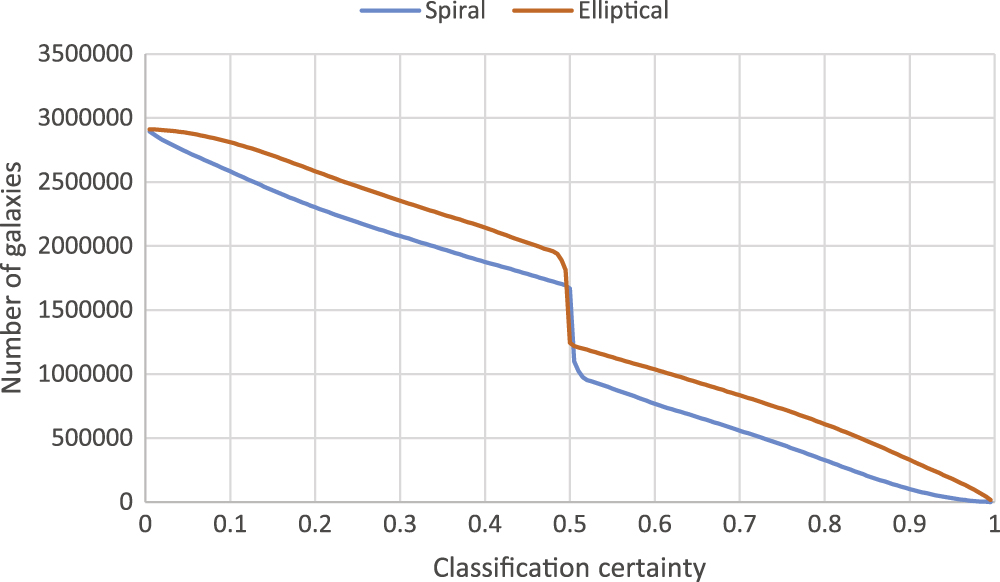
Number of spiral and elliptical galaxies classified above different certainty levels. Cutting at the 54% certainty level for spirals and 80% for ellipticals leaves ~900,000 and ~600,000 spiral and elliptical galaxies, respectively. [Kuminski et al. 2016]
The authors acknowledge that completeness is a problem; half the data had to be cut to achieve this level of accuracy. Sacrificing some data can still result in very large catalogs, however — and as surveys become more powerful and large databases become more prevalent, algorithms such as this one will likely become critical to the scientific process.
Citation
Evan Kuminski and Lior Shamir 2016 ApJS 223 20. doi:10.3847/0067-0049/223/2/20