
How do we find the signals of exoplanets lurking in the vast quantity of data that comes out of a mission like Kepler or the Transiting Exoplanet Survey Satellite (TESS)? A new study has some suggestions for how best to get computers to do the heavy lifting for us.
Managing a Mess of Data
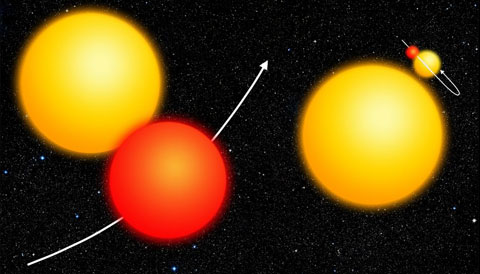
Two common false positives — grazing eclipsing binaries (left) and background eclipsing binaries (right) — can mimic the signal of a transiting planet. [NASA/Ames Research Center]
Given the number of light curves that need classifying, we can use any automated help we can get. Enter machine learning, a process by which computers can be trained to identify patterns and make decisions. Using a tool called deep learning, scientists have already shown that machines can do a pretty good job of automatically classifying Kepler transit signals as either exoplanets or false positives. But can we do even better?
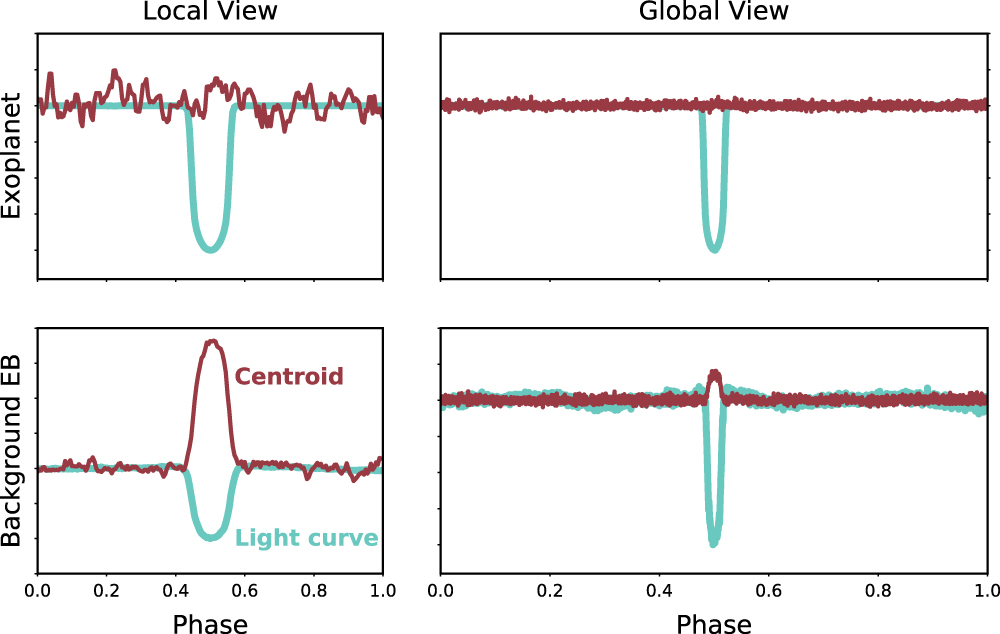
Local (left) and global (right) views of the light curves (cyan) and centroids (maroon) for an example confirmed planet (top) and background eclipsing binary (bottom). Click for a closer look. [Ansdell et al. 2018]
Insider Knowledge
Ansdell and collaborators started with a basic machine-learning model that classified signals based on straightforward local and global views of the light curves. To improve upon it, they added scientific domain knowledge — information or insight that might not be generally known, but can be provided by a domain expert.
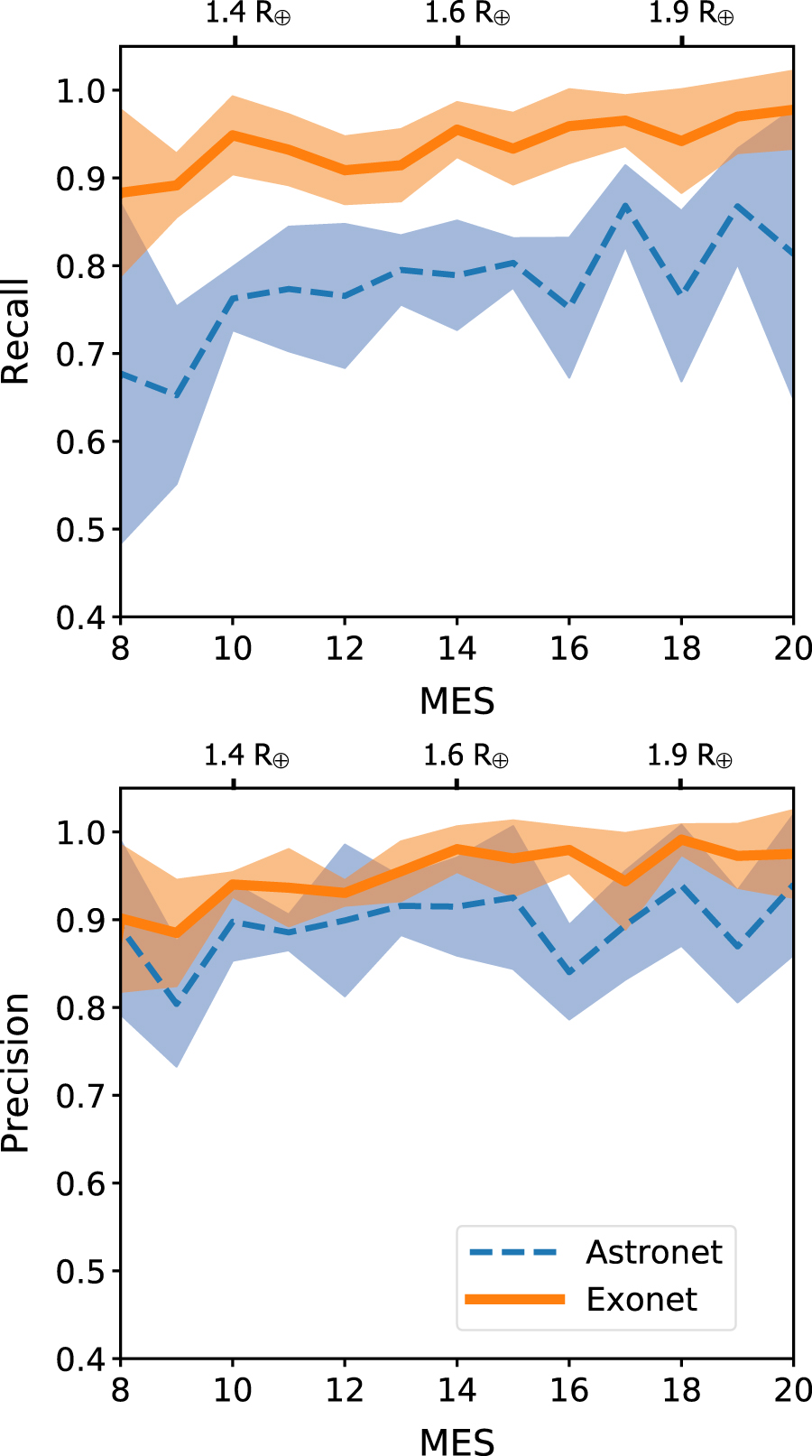
Recall (top; the fraction of true planets recovered) and precision (bottom; the fraction of classifications that are correct) of the Exonet model, as a function of MES, a measure of the signal-to-noise of candidate transits. [Ansdell et al. 2018]
More Planets to Come
How did Ansdell and collaborators do? Using their modified model, “Exonet”, a computer can classify a Kepler data set with 97.5% accuracy and 98% average precision. That means that 97.5% of its classifications — exoplanet or false-positive — are correct, and an average of 98% of transits classified as planets are true planets. Not bad, for a machine!
One of the added benefits of the authors’ model is that it is ideal for generalization — for example, from Kepler to TESS data. The authors are currently working on a study using Exonet to classify simulated TESS data. And yesterday’s first public data release from TESS has provided plenty of fresh data to work with in the future!
Citation
“Scientific Domain Knowledge Improves Exoplanet Transit Classification with Deep Learning,” Megan Ansdell et al 2018 ApJL 869 L7. doi:10.3847/2041-8213/aaf23b
3 Comments
Pingback:AAS Nova – New
Pingback:A Computer System Found a Turtle Hiding Out in a Cloud of 'Quantum Fireworks' - Science and Tech News
Pingback:كمبيوتر يرصد سلحفاة يختبئ في سحابة من "الألعاب النارية الكم" - Digital tech