
Every year, astronomers submit over a thousand proposals requesting time on the Hubble Space Telescope (HST). Currently, humans must sort through each of these proposals by hand before sending them off for review. Could this burden be shifted to computers?
A Problem of Volume

Astronomer Molly Peeples gathered stats on the HST submissions sent in last week for the upcoming HST Cycle 25 (the deadline was Friday night), relative to previous years. This year’s proposal round broke the record, with over 1200 proposals submitted in total for Cycle 25. [Molly Peeples]
Ideally, each proposal will be read by reviewers that have scientific expertise relevant to the proposal topic: if a proposal requests HST time to study star formation, for instance, then the reviewers assigned to it should have research expertise in star formation.
How does this matching of proposals to reviewers occur? The current method relies on self-reported categorization of the submitted proposals. This is unreliable, however; proposals are often mis-categorized by submitters due to misunderstanding or ambiguous cases.
As a result, the Science Policies Group at the Space Telescope Science Institute (STScI) — which oversees the review of HST proposals — must go through each of the proposals by hand and re-categorize them. The proposals are then matched to reviewers with self-declared expertise in the same category.
With the number of HST proposals on the rise — and the expectation that the upcoming James Webb Space Telescope (JWST) will elicit even more proposals for time than Hubble — scientists at STScI and NASA are now asking: could the human hours necessary for this task be spared? Could a computer program conceivably do this matching instead?
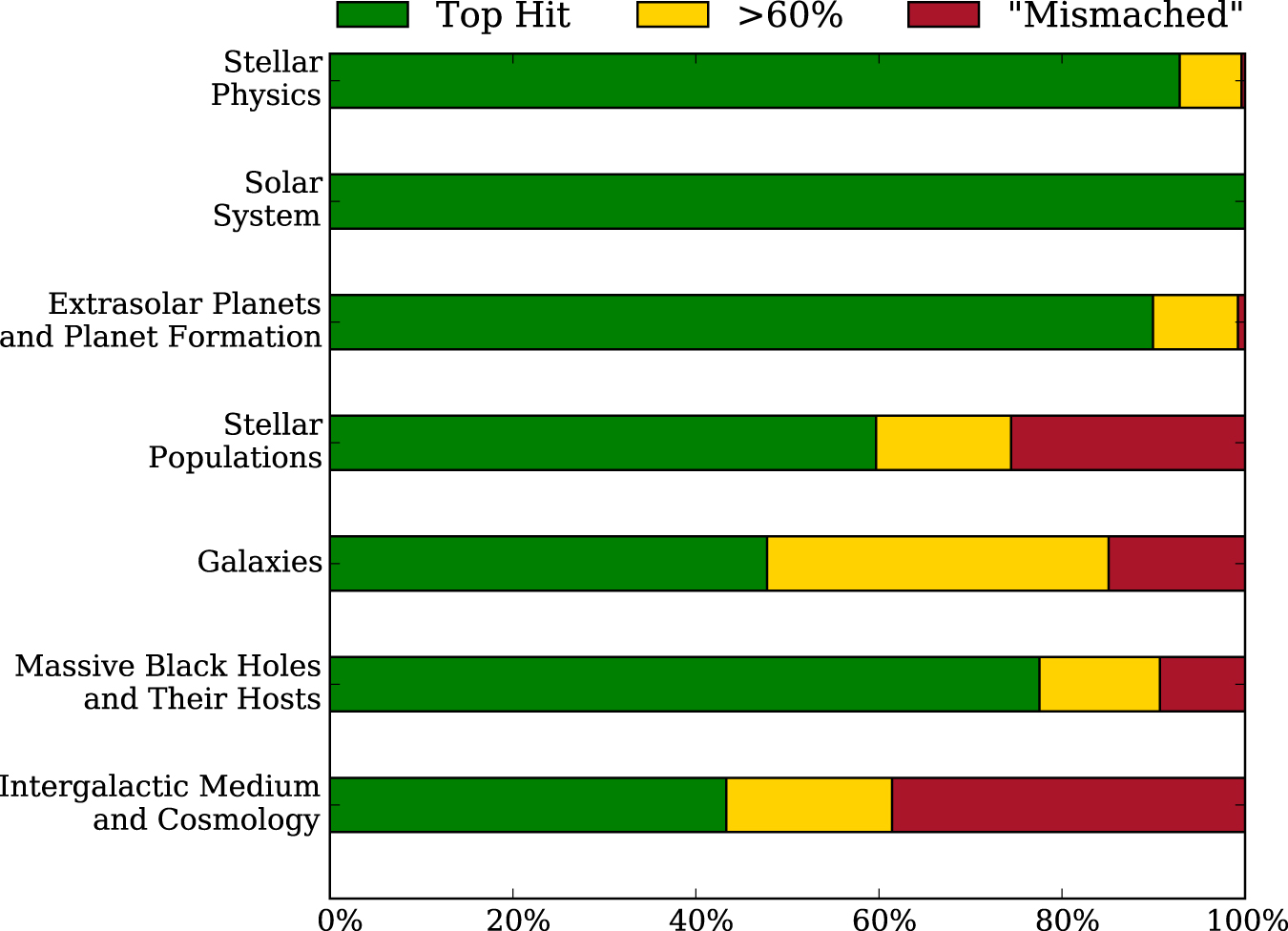
Comparison of PACMan’s categorization to the manual sorting for HST Cycle 24 proposals. Green: proposals similarly categorized by both. Yellow: proposals whose manual classifications are within the top 60% of sorted PACMan classifications. Red: proposals categorized differently by each. [Strolger et al. 2017]
Introducing PACMan
Led by Louis-Gregory Strolger (STScI), a team of scientists has developed PACMan: the Proposal Auto-Categorizer and Manager. PACMan is what’s known as a Naive Bayesian classifier; it’s essentially a spam-filtering routine that uses word probabilities to sort proposals into multiple scientific categories and identify people to serve on review panels in those same scientific areas.
PACMan works by looking at the words in a proposal and comparing them to those in a training set of proposals — in this case, the previous year’s HST proposals, sorted by humans. By using the training set, PACMan “learns” how to accurately classify proposals.
PACMan then looks up each reviewer on the Astrophysical Data System (ADS) and compiles the abstracts from the reviewer’s past 10 years’ worth of scientific publications. This text is then evaluated in a similar way to the text of the proposals, determining each reviewer’s suitability to evaluate a proposal.
How Did It Do?
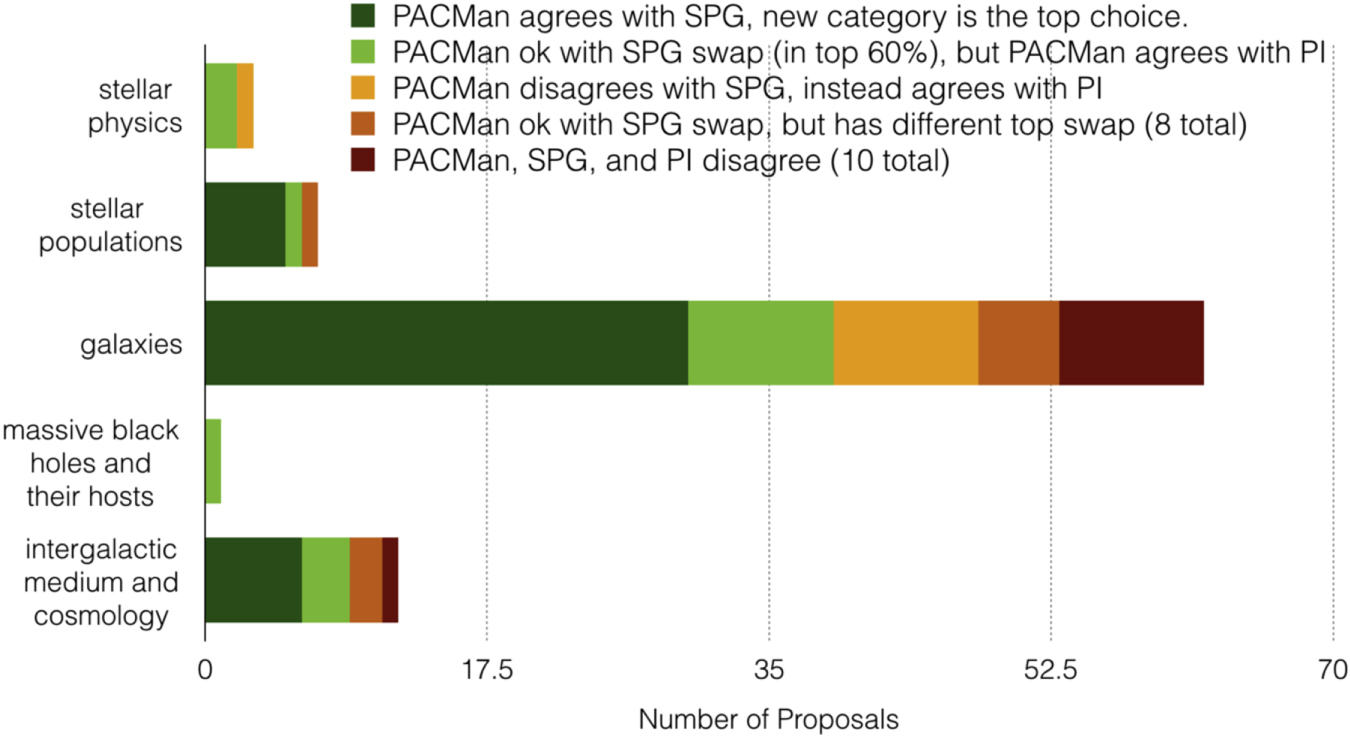
Comparison of PACMan sorting to manual sorting, specifically for the HST Cycle 24 proposals that were recategorized by the Science Policies Group (SPG) from what the submitter (PI) selected. Of these swaps, 48% would have been predicted by PACMan. [Strolger et al. 2017]
PACMan’s results were also consistent for reviewers: it found that nearly all of the reviewers (92%) asked to serve in the last cycle were appropriate reviewers for the subject area based on their ADS publication record.
There are still some hiccups in automating this process — for instance, finding the reviewers on ADS can require human intervention due to names not being unique. As the scientific community moves toward persistent and distinguishable identifiers (like ORCIDs), however, this problem will be mitigated.
Strolger and collaborators believe that PACMan demonstrates a promising means of increasing the efficiency and impartiality of the HST proposal sorting process. This tool will likely be used to assist or replace humans in this process in future HST and JWST cycles.
Citation
Louis-Gregory Strolger et al 2017 AJ 153 181. doi:10.3847/1538-3881/aa6112
1 Comment
Pingback:April 10, 2017 | Colorado Space News